Abstract
Despite recent advances in text-to-image (T2I) generation, models still struggle to accurately render
prompt-specified text with correct spatial layout—especially in multi-span, structured settings.
This challenge is driven not only by the lack of datasets that align prompts with the exact text and layout
expected in the image, but also by the absence of effective metrics for evaluating layout quality.
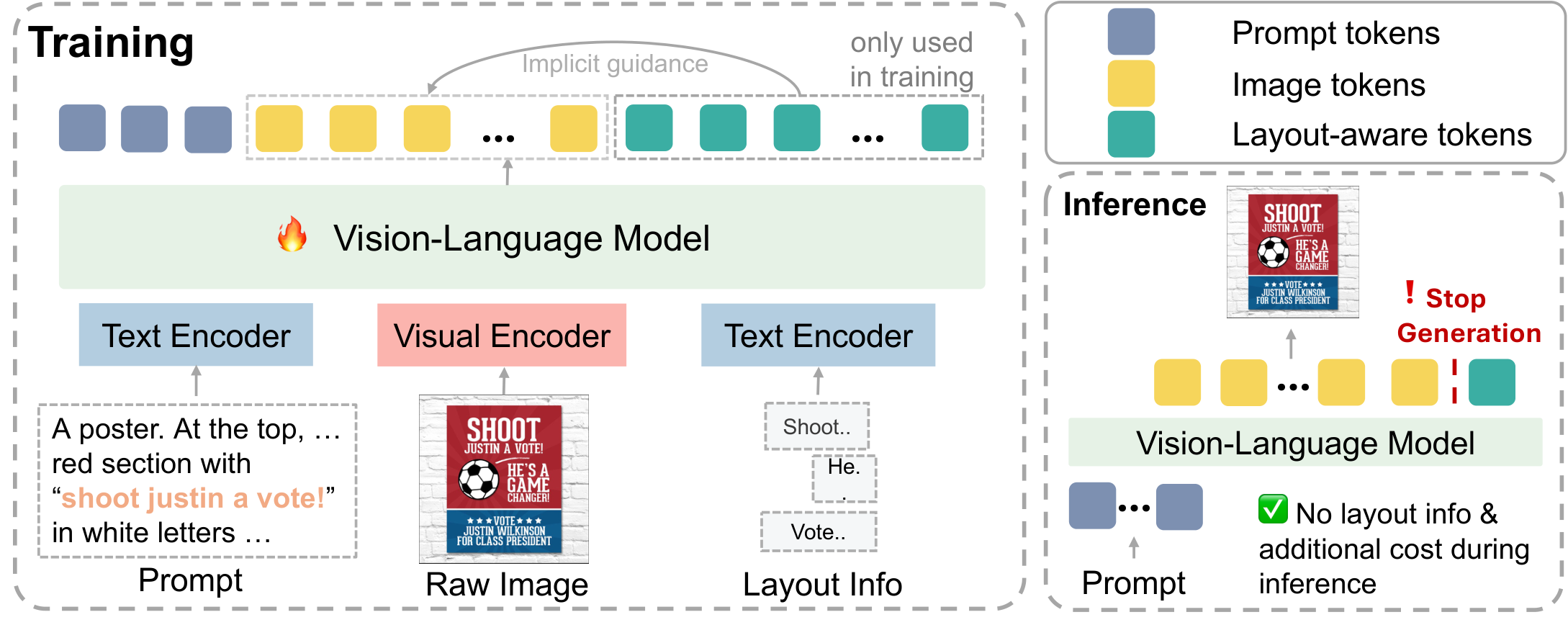
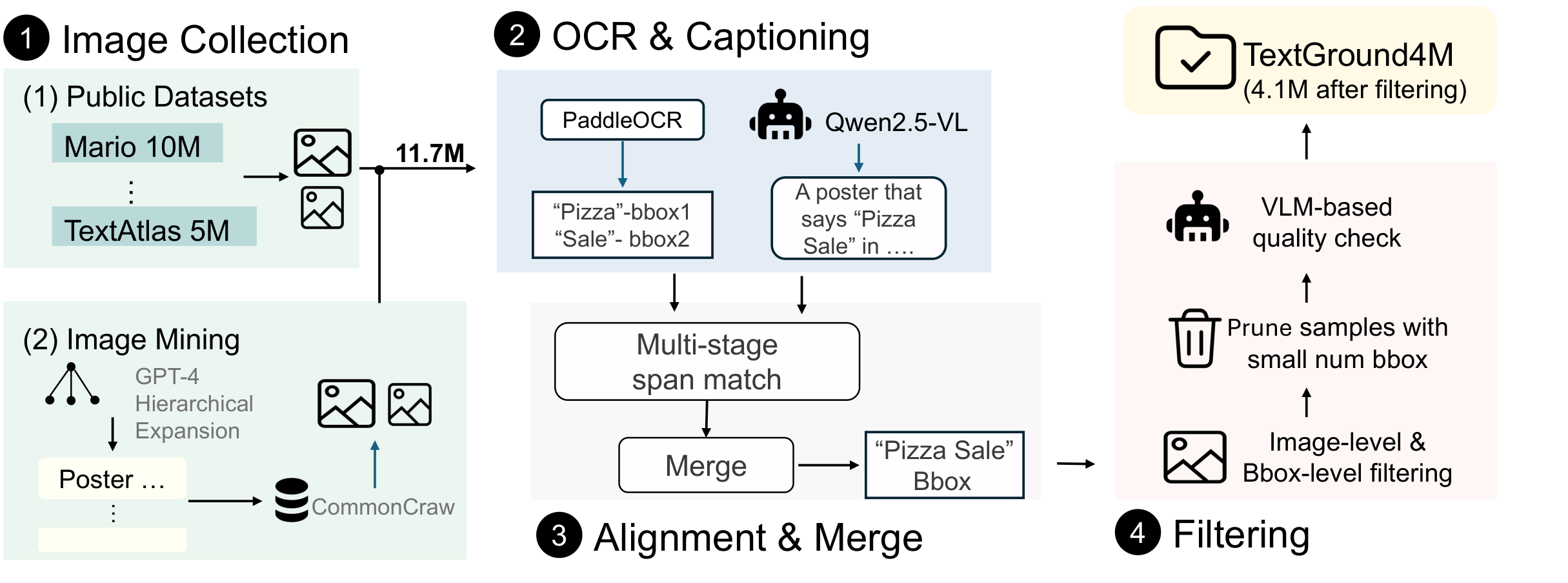
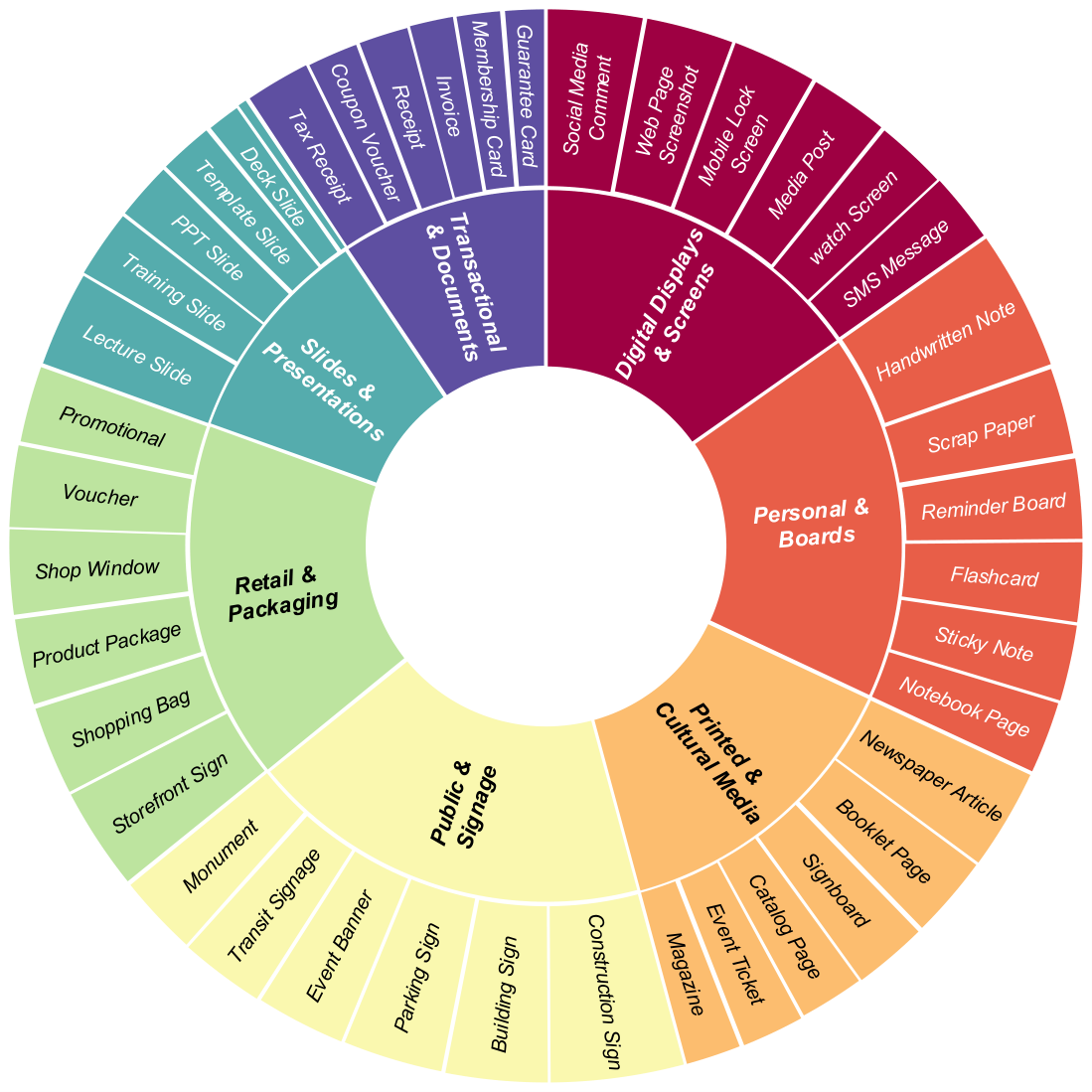
To address these issues, we introduce TextGround4M, a large-scale dataset of over 4 million prompt-image pairs, each annotated with span-level text grounded in the prompt and corresponding bounding boxes, enabling fine-grained supervision for layout-aware, prompt-grounded text rendering. Building on this, we propose a lightweight training strategy for autoregressive T2I models that appends layout-aware span tokens during training, without altering model architecture or inference behavior. We further construct TextGround-Bench, a benchmark with stratified layout complexity, and introduce two new layout-aware metrics to address the long-standing lack of spatial evaluation in text rendering.
To address these issues, we introduce TextGround4M, a large-scale dataset of over 4 million prompt-image pairs, each annotated with span-level text grounded in the prompt and corresponding bounding boxes, enabling fine-grained supervision for layout-aware, prompt-grounded text rendering. Building on this, we propose a lightweight training strategy for autoregressive T2I models that appends layout-aware span tokens during training, without altering model architecture or inference behavior. We further construct TextGround-Bench, a benchmark with stratified layout complexity, and introduce two new layout-aware metrics to address the long-standing lack of spatial evaluation in text rendering.
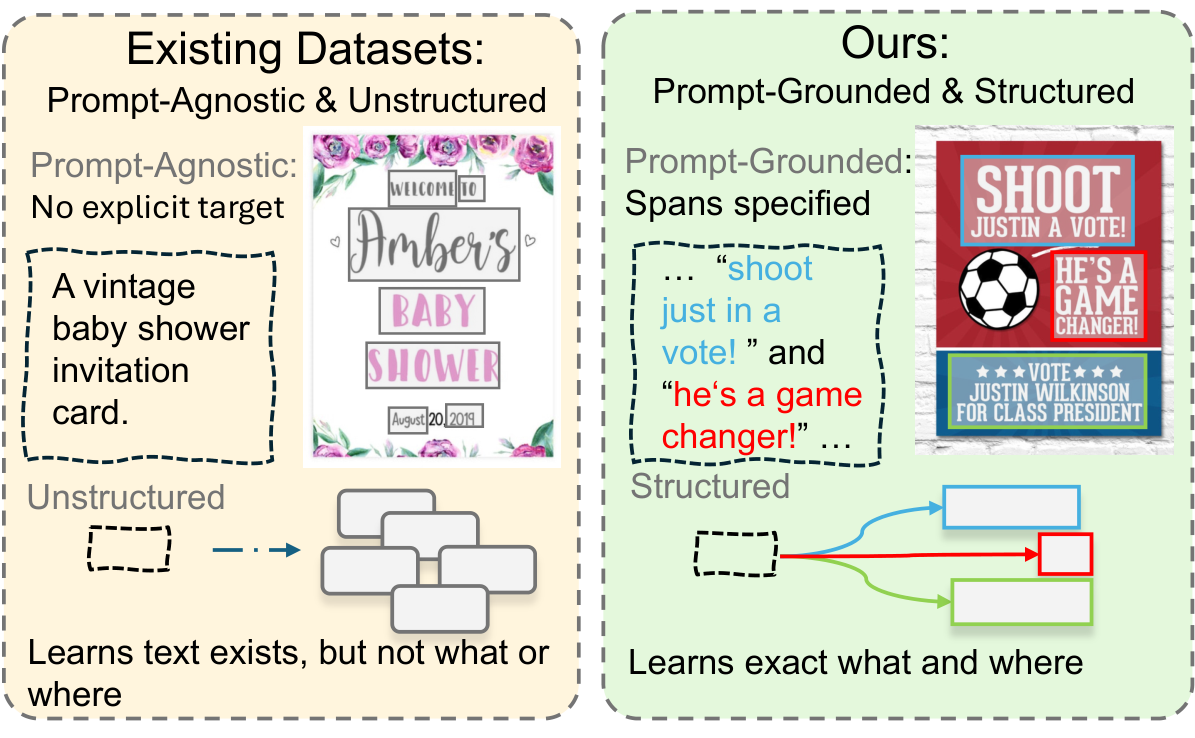
Comparison with existing datasets. Prior datasets annotate all visible text without prompt grounding or layout structure. TextGround4M provides prompt-aligned, span-level annotations with precise spatial bounding boxes, enabling faithful and layout-aware text rendering.